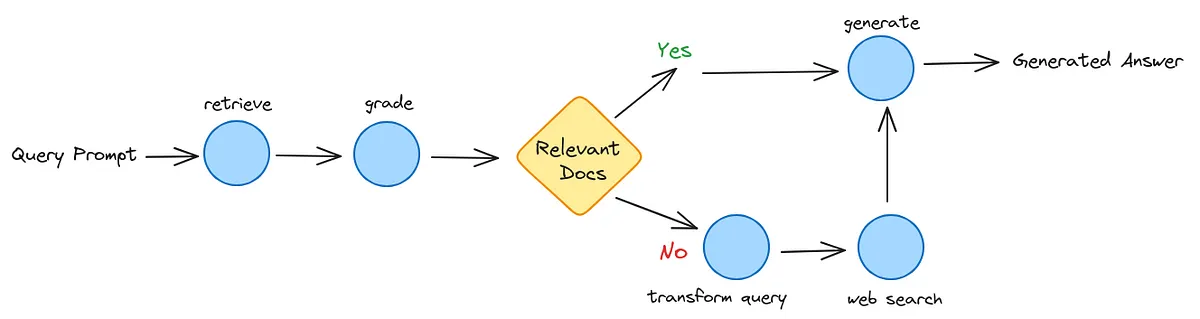
Implementing Corrective RAG in the Easiest Way
Even though text-generation models are good at generating content, they sometimes need to improve in returning facts. This happens because of the way they are trained.
Even though text-generation models are good at generating content, they sometimes need to improve in returning facts. This happens because of the way they are trained.
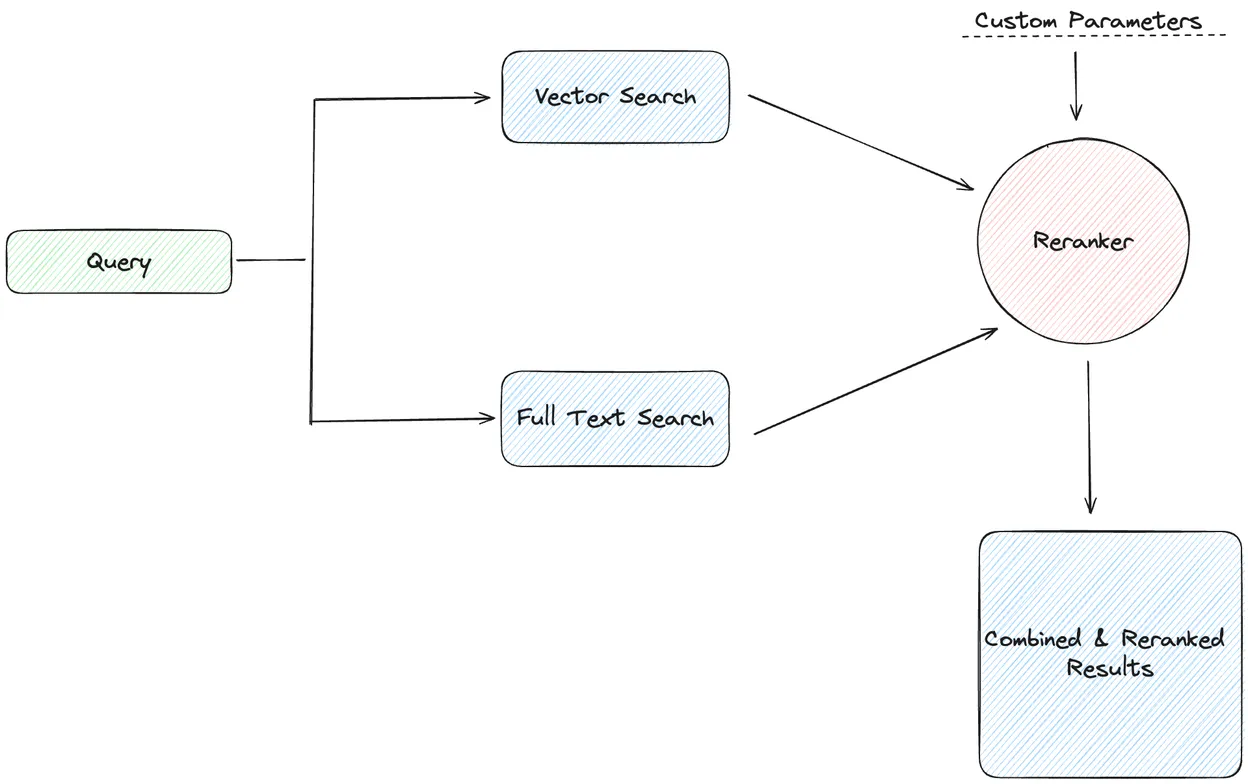
Combine keyword and vector search for higher‑quality results with LanceDB. This post shows how to run hybrid search and compare rerankers (linear combination, Cohere, ColBERT) with code and benchmarks.
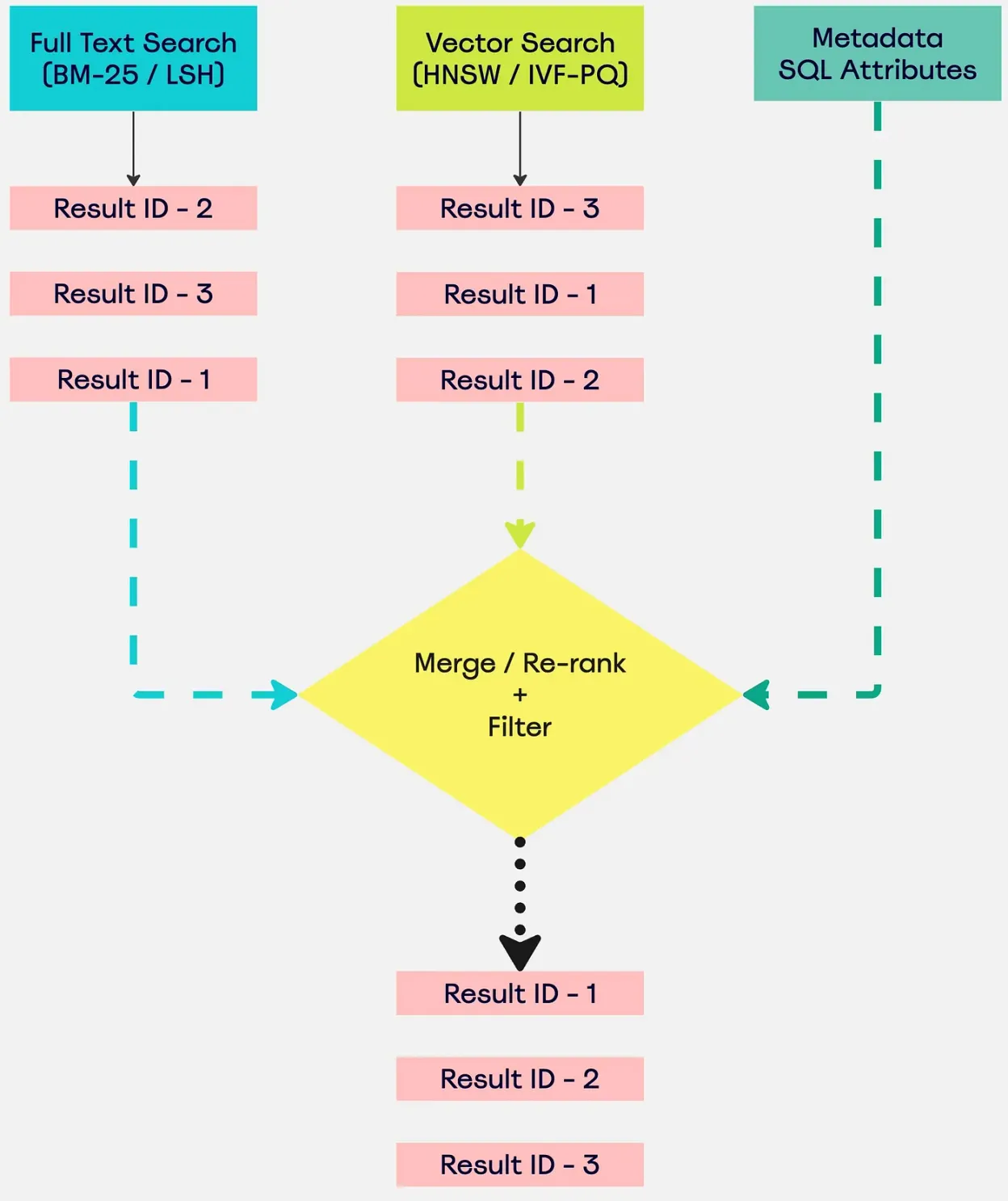
Get about hybrid search: rag for real-life production-grade applications. Get practical steps, examples, and best practices you can use now.
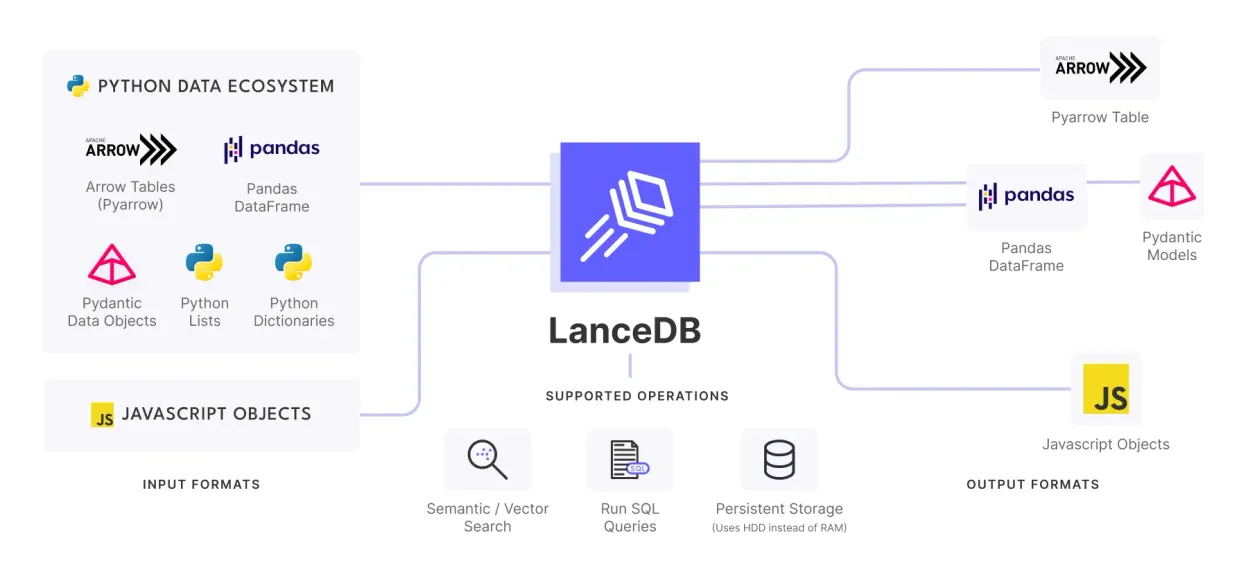
Discover about efficient rag with compression and filtering. Get practical steps, examples, and best practices you can use now.
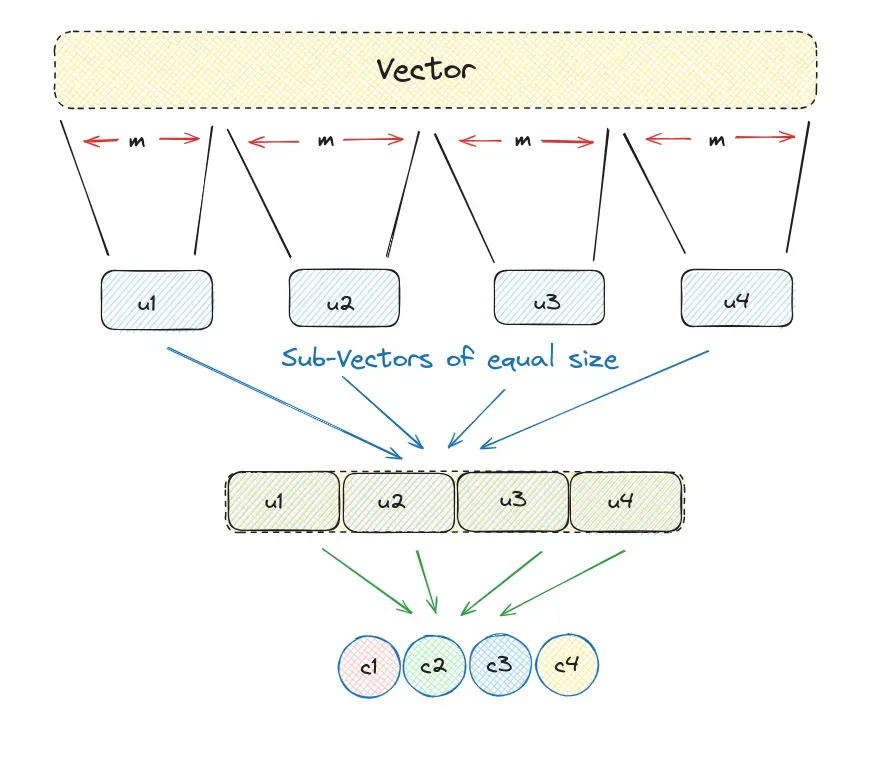
Compress vectors with PQ and accelerate retrieval with IVF_PQ in LanceDB. The tutorial explains the concepts, memory savings, and a minimal implementation with search tuning knobs.
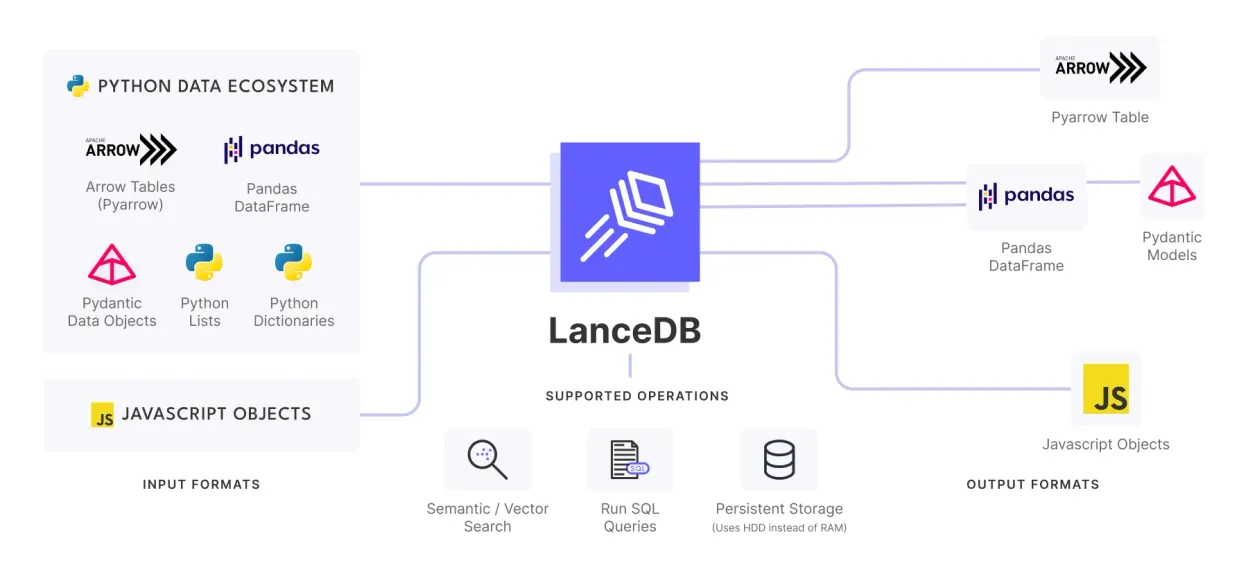
Get about modified rag: parent document & bigger chunk retriever. Get practical steps, examples, and best practices you can use now.
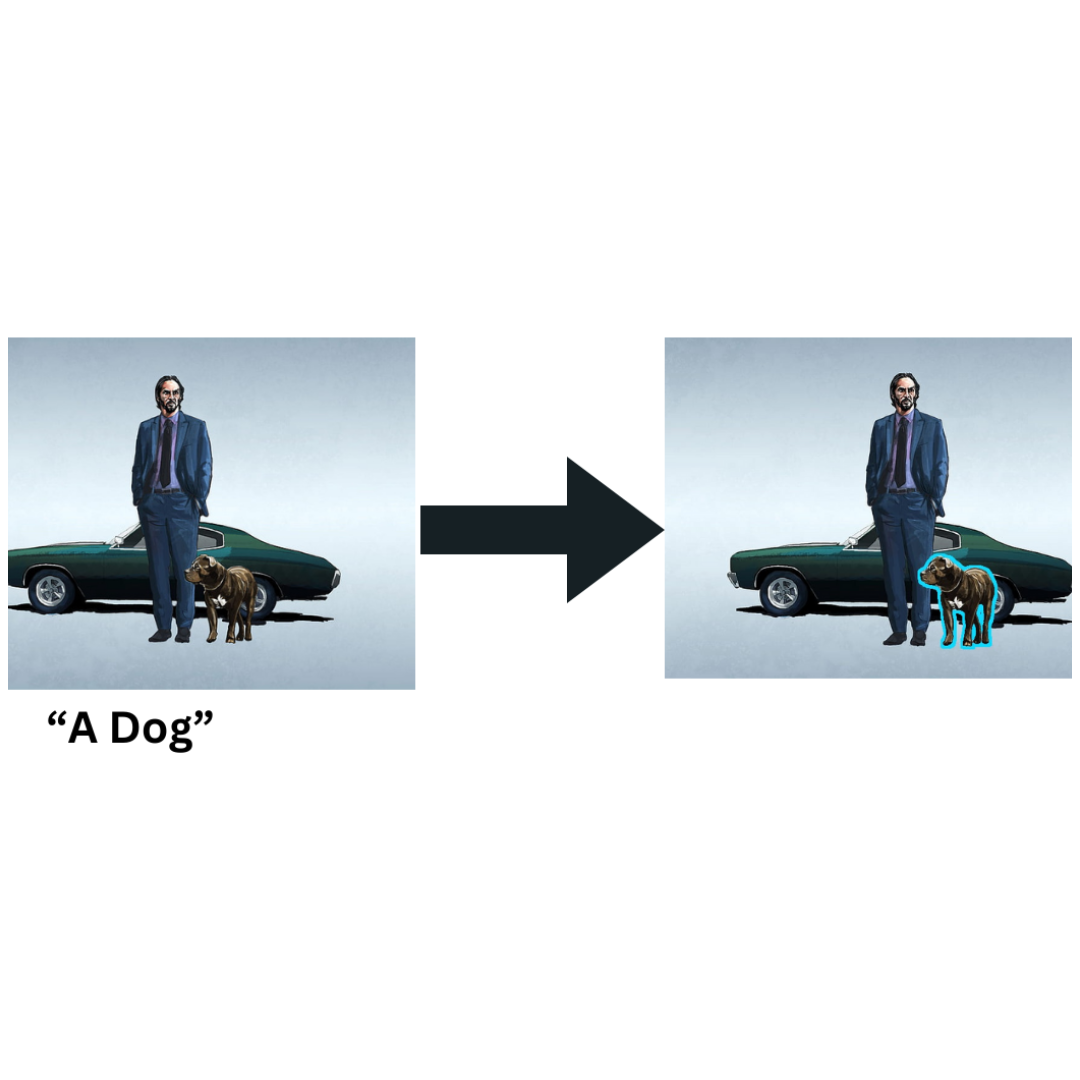
Get about search within an image with segment anything. Get practical steps, examples, and best practices you can use now.
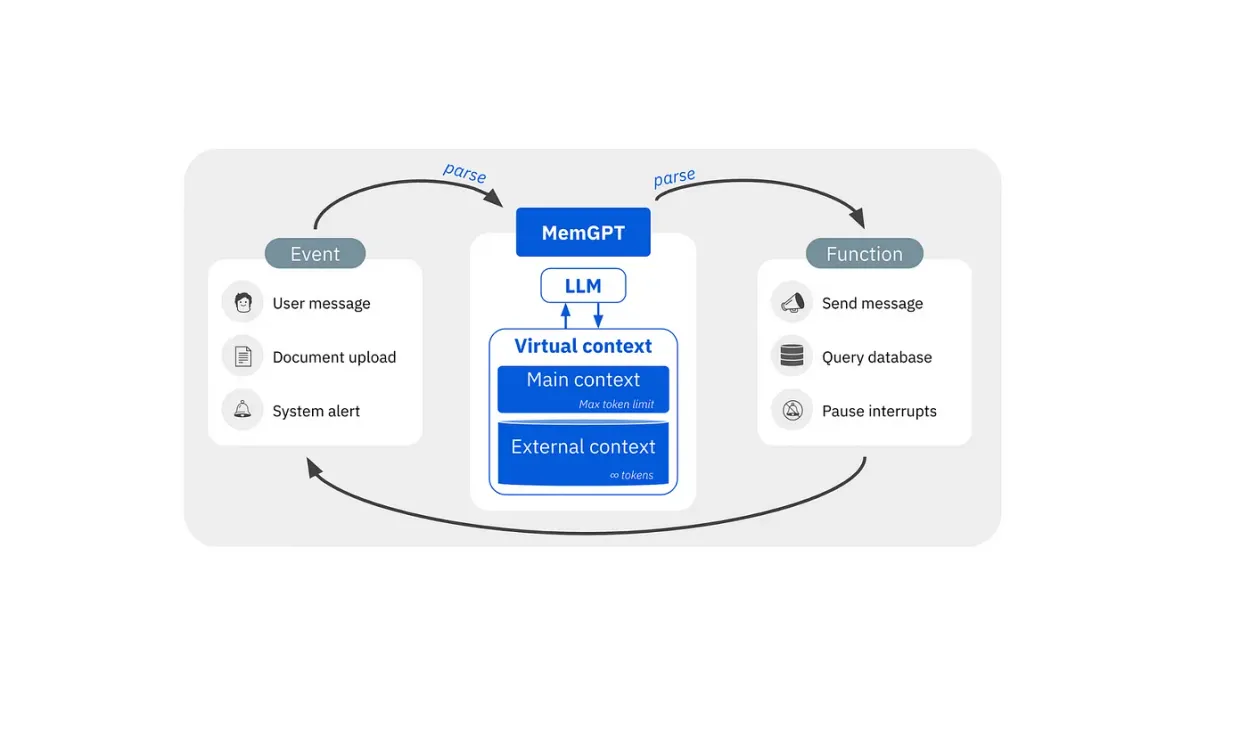
Explore about memgpt: os inspired llms that manage their own memory. Get practical steps, examples, and best practices you can use now.
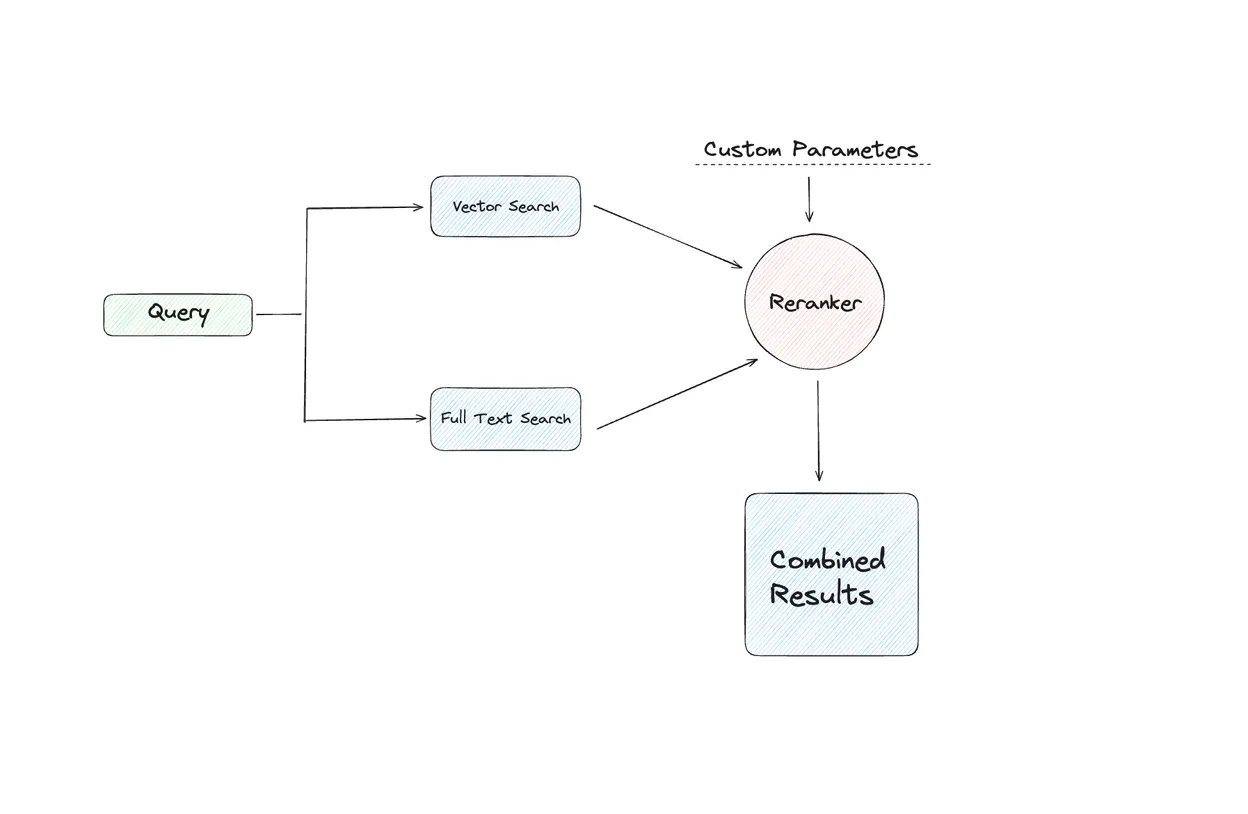
Have you ever thought about how search engines find exactly what you're looking for? They usually use a mix of looking for specific words and understanding the meaning behind them.